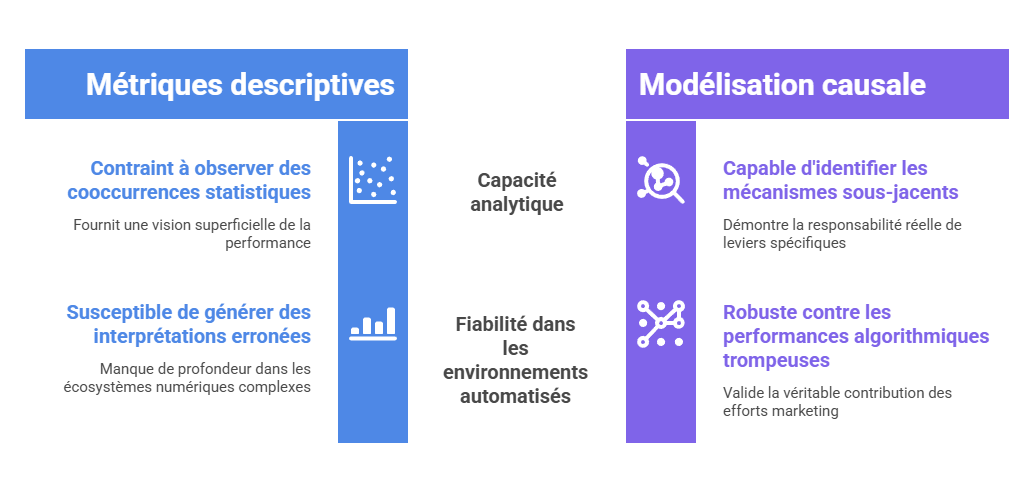
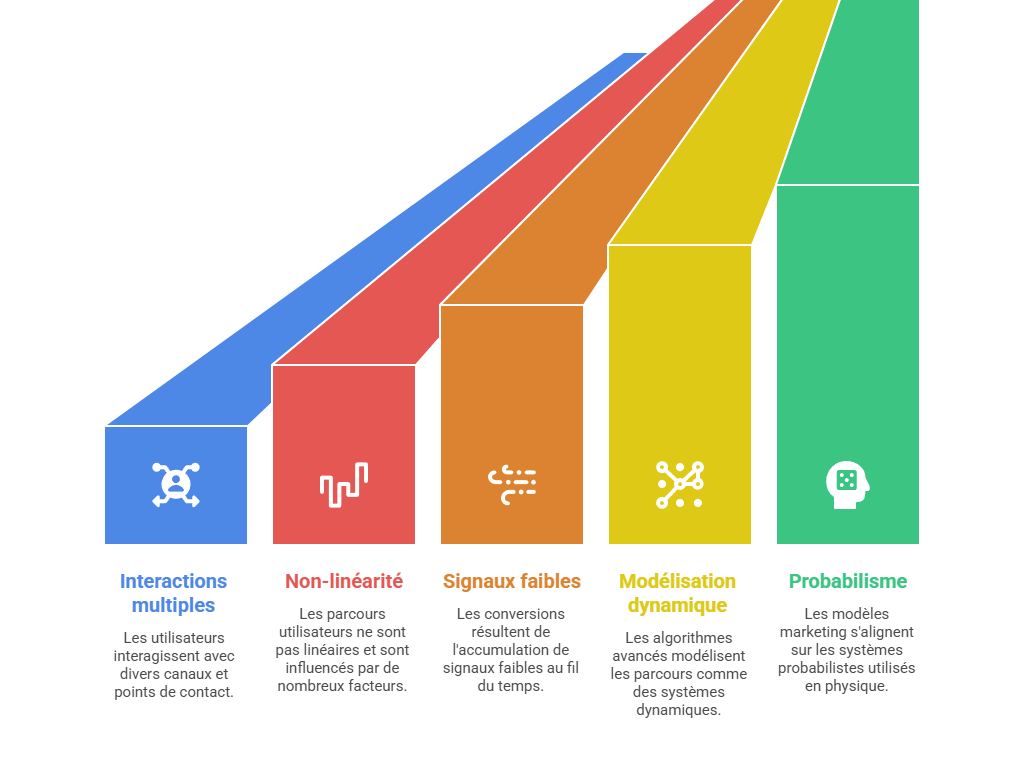
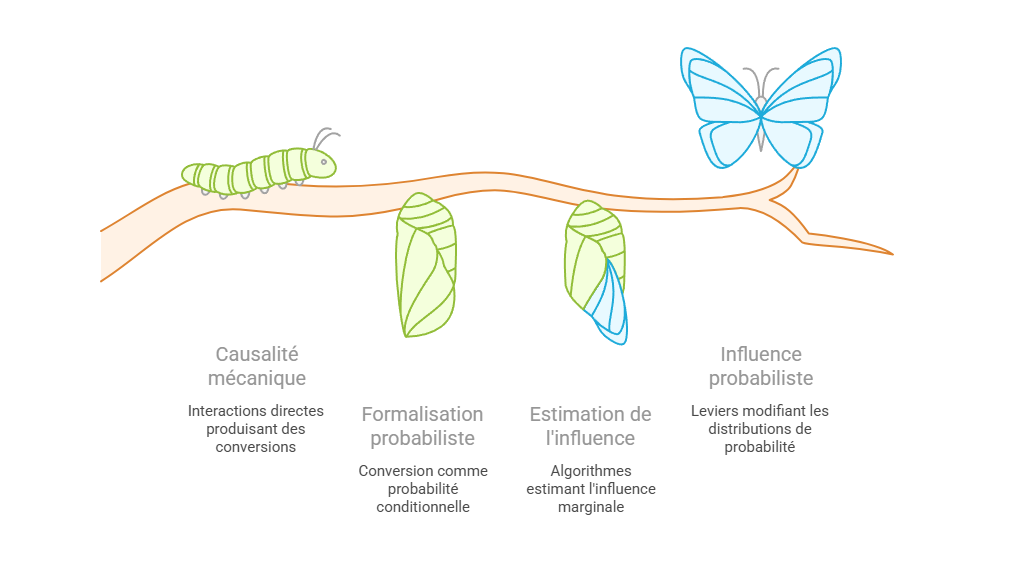
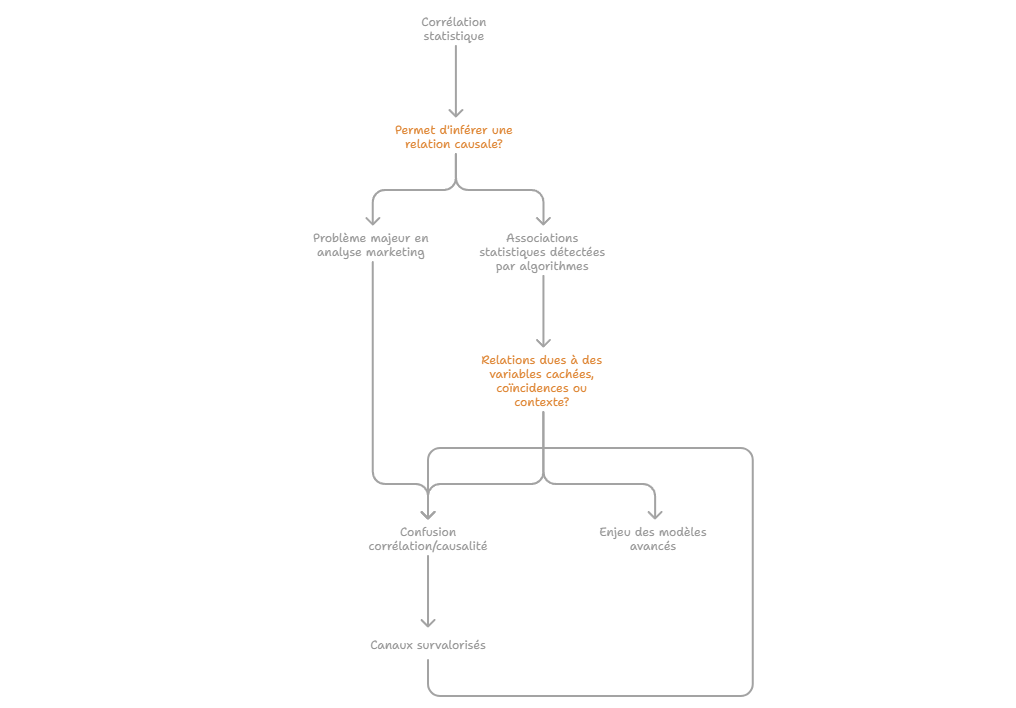
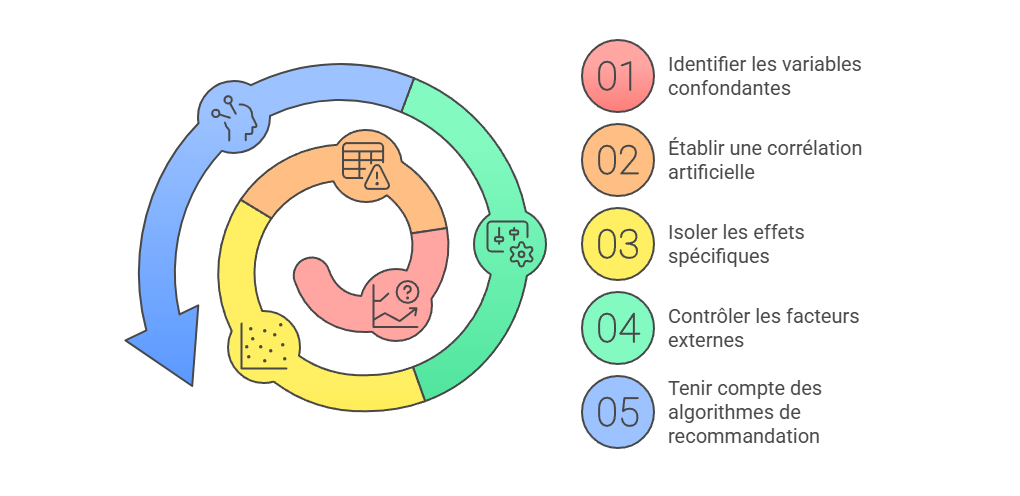
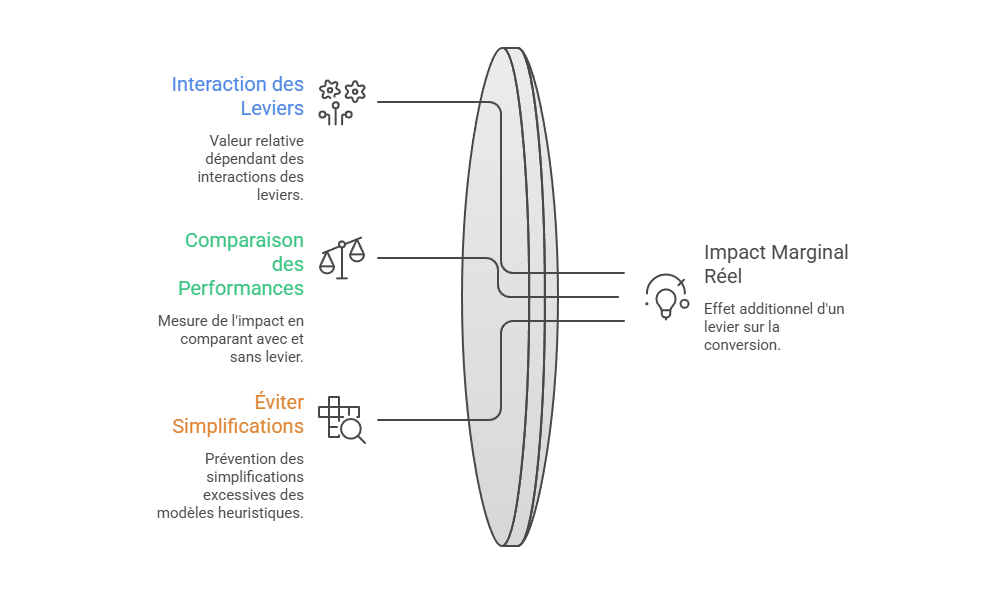
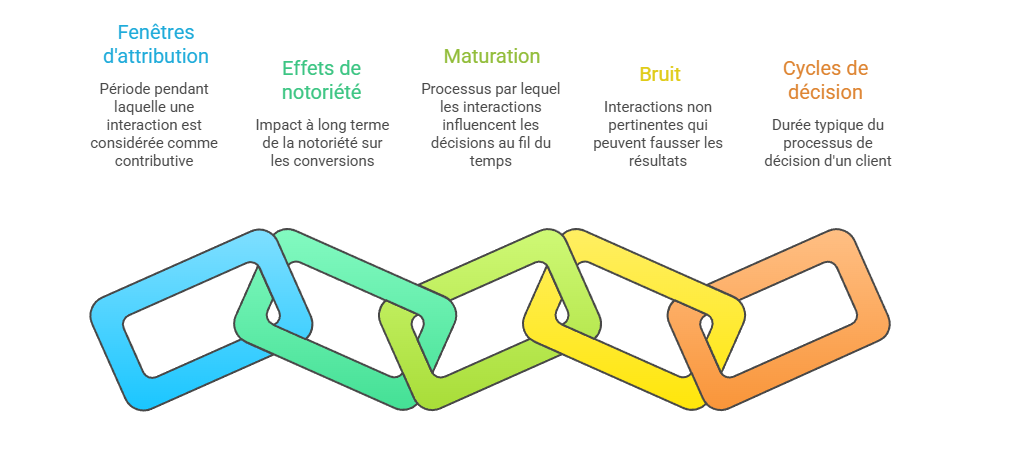
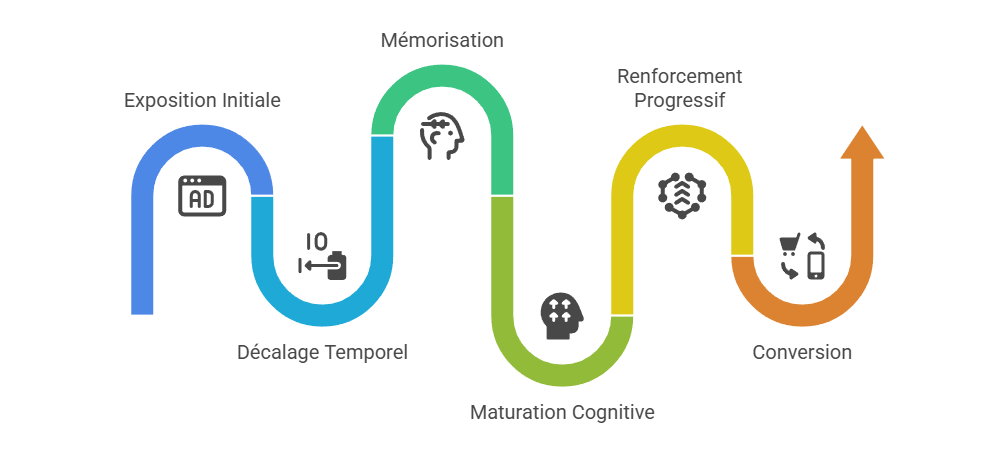
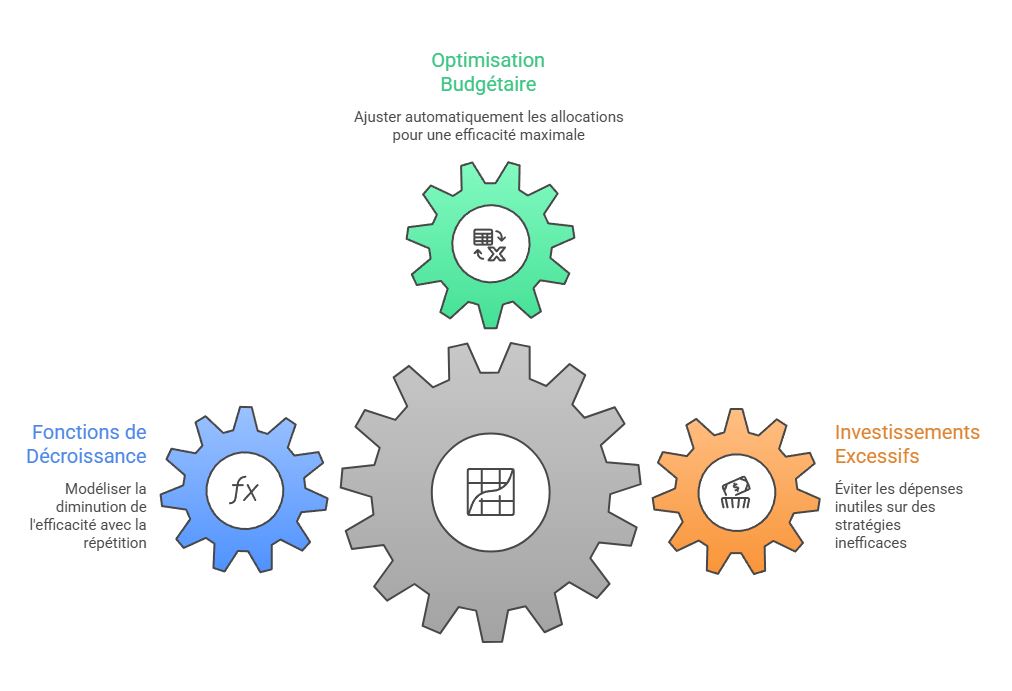
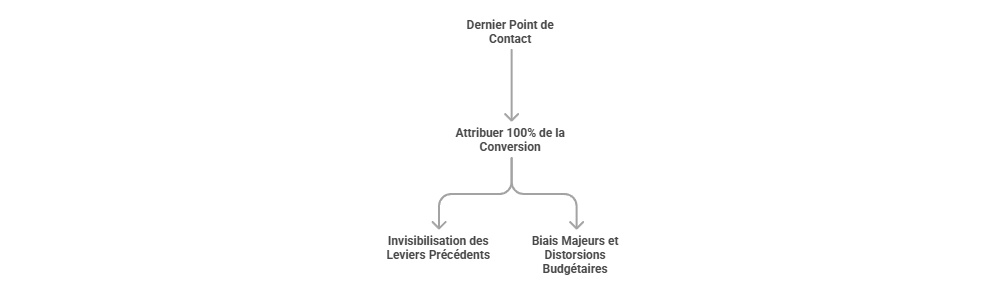
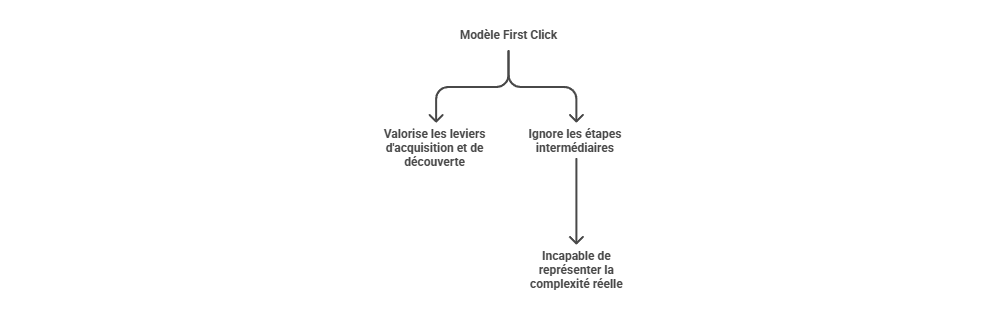
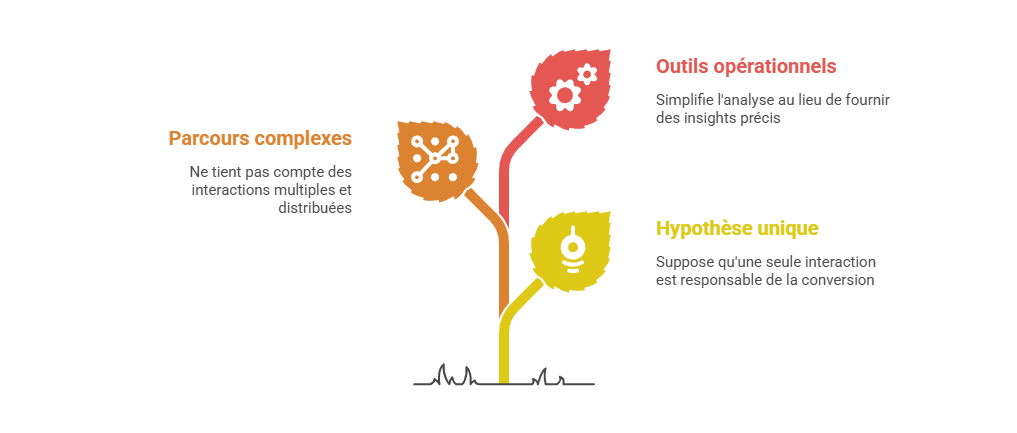
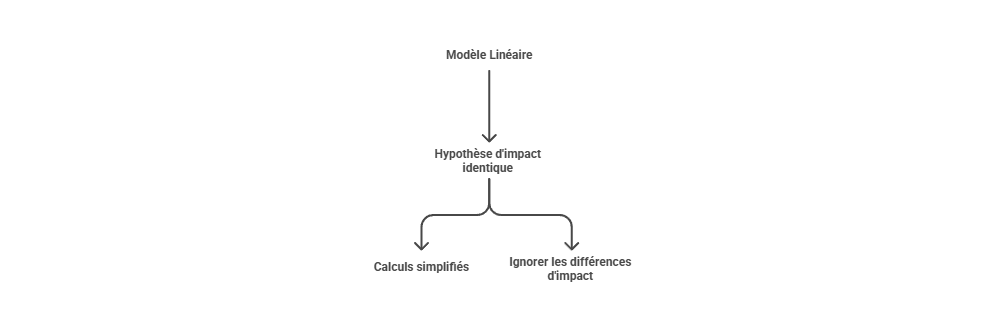
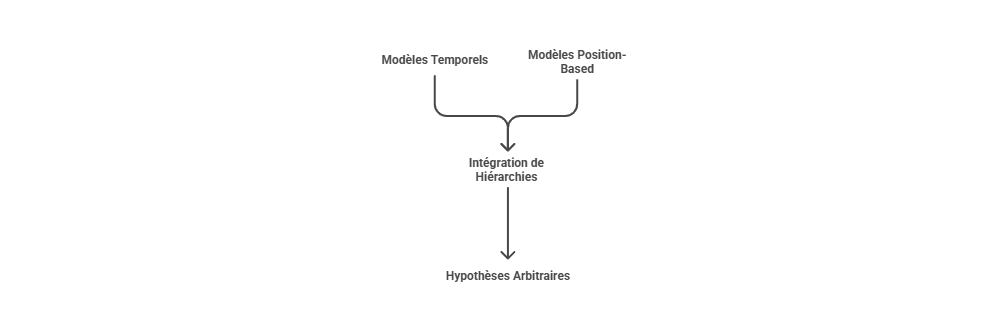
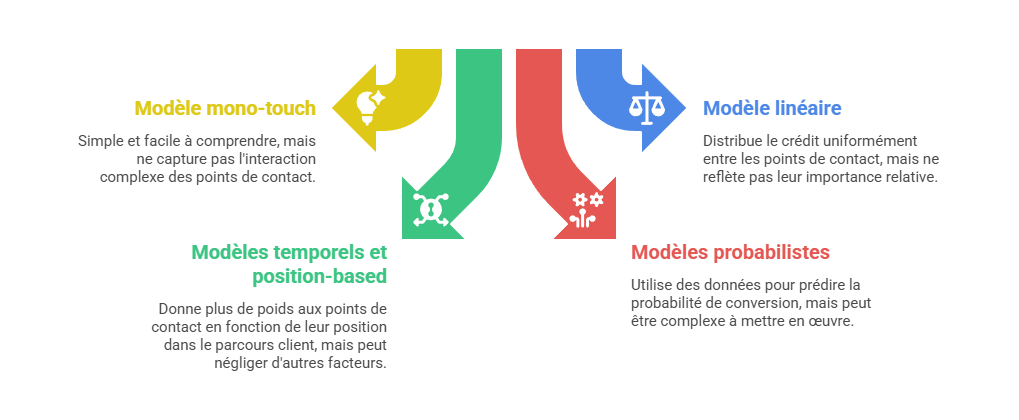
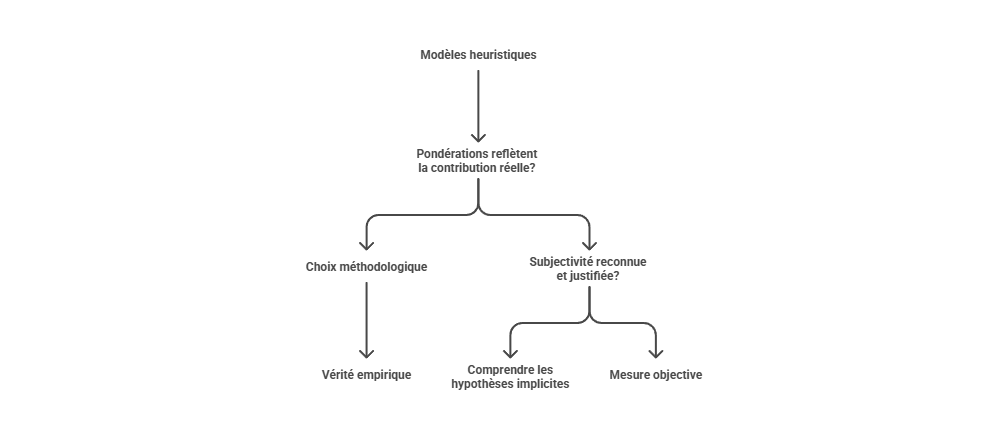
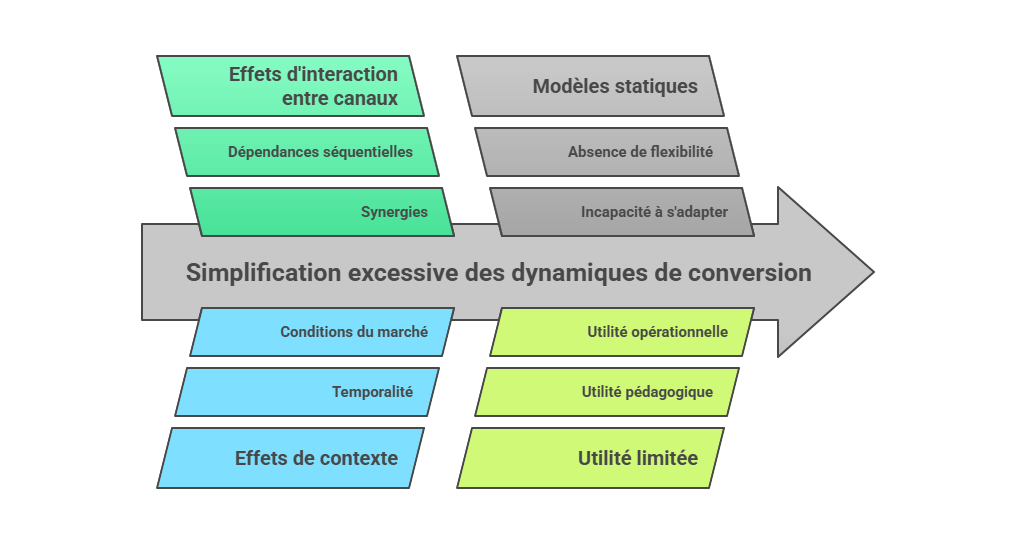
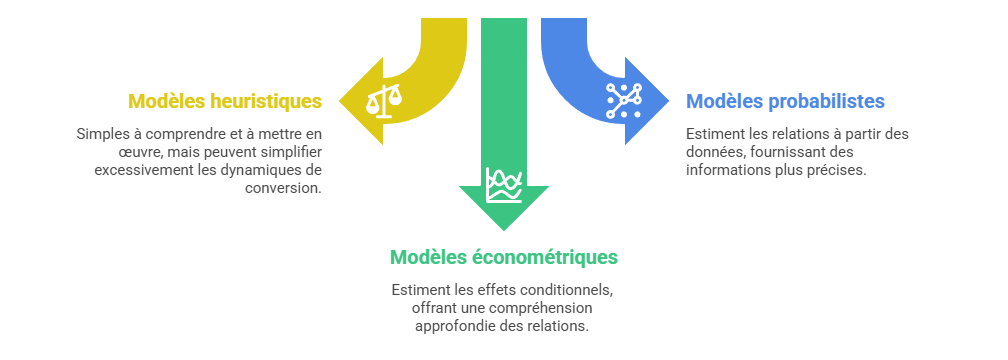
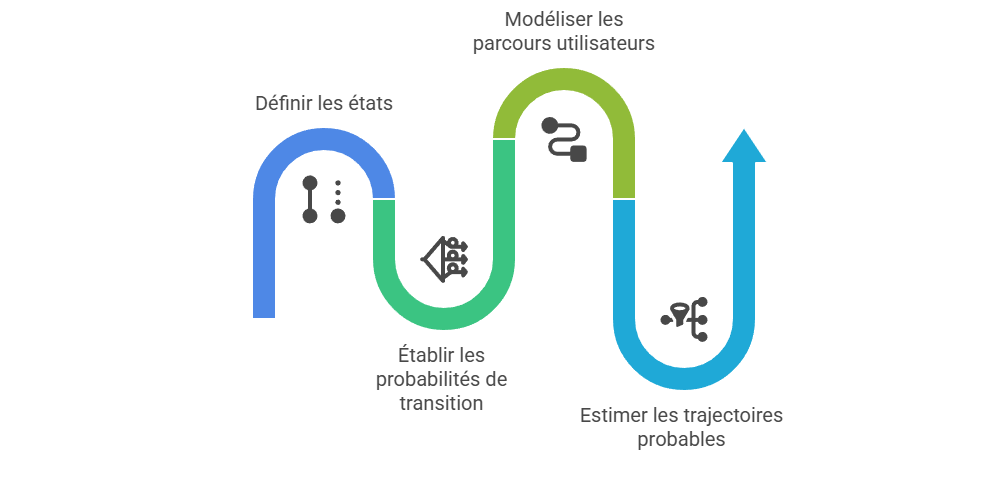
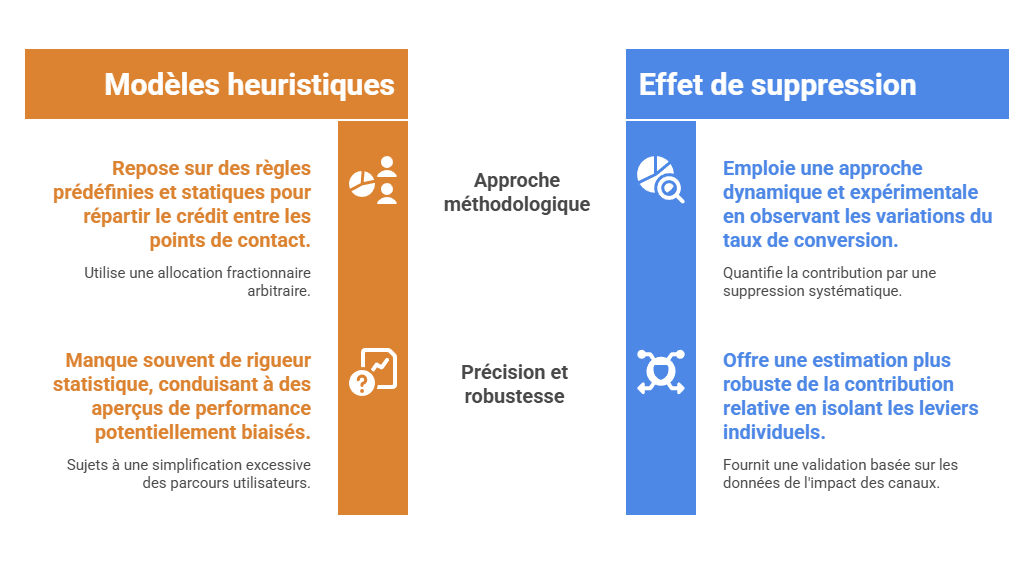
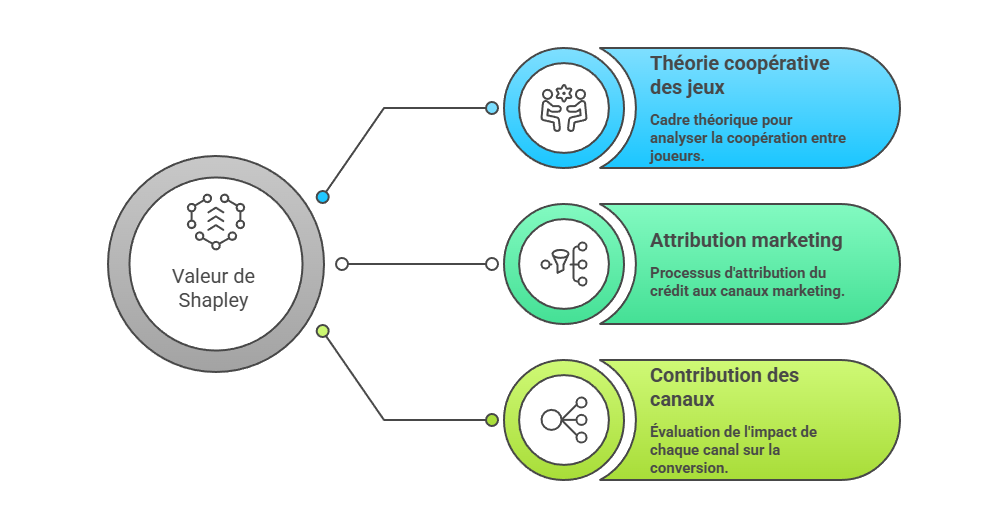
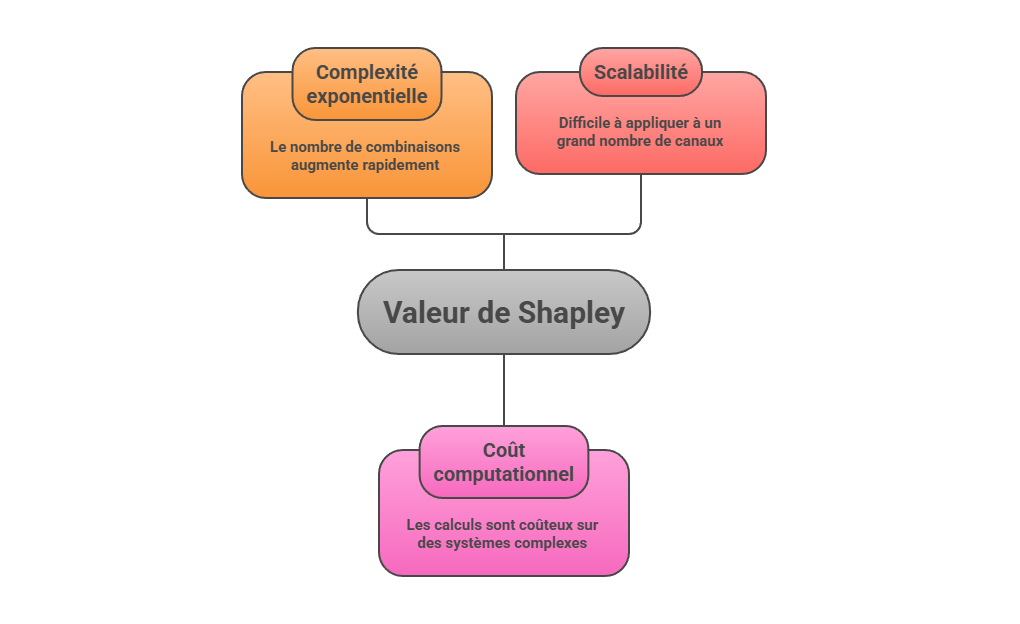
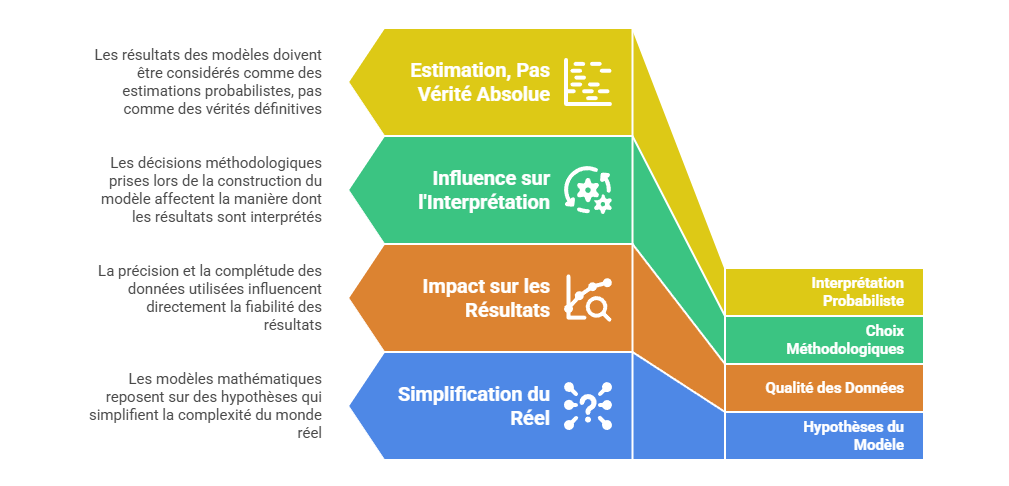
Les métriques descriptives constituent le premier niveau de lecture de la performance marketing, mais elles ne suffisent pas à expliquer les mécanismes qui produisent la conversion. Un taux de clic, un ROAS ou un CPA décrivent un résultat observé, sans établir que le canal associé en est la cause. L’enjeu consiste à distinguer l’observation statistique de l’intervention causale : une donnée peut indiquer qu’un phénomène accompagne une conversion, sans démontrer qu’il l’a provoquée. C’est précisément le point d’entrée vers l’attribution avancée, qui cherche à dépasser la simple lecture de dashboard pour reconstruire les relations entre leviers, parcours et résultats.
La probabilité conditionnelle observationnelle, notée P(Y|X), décrit ce que l’on observe lorsque X est présent. La probabilité interventionnelle, notée P(Y|do(X)), cherche à représenter ce qui se passerait si l’on imposait X comme action. Cette distinction, issue de l’inférence causale, rappelle qu’une relation observée dans les données ne suffit pas à établir un effet causal.